Čo je faktorová analýza
Faktorová analýza na základe vzájomných vzťahov medzi viacerými premennými identifikuje tie, ktoré spolu vzájomne súvisia. Z tých, ktoré vzájomne úzko súvisia vytvára takzvané faktory, a tým redukuje počet premenných do menšieho počtu faktorov. Inými slovami, faktorová analýza pomocou skúmania vzájomných vzťahov medzi premennými (korelačnými maticami) sa snaží identifikovať faktory v skupine premenných, ktoré znížia počet premenných.
Premenné, ktoré skúmame a ktorých je zvyčajne veľa môžeme nazvať manifestnými premennými. A zredukované premenné – faktory môžeme nazvať latentnými premennými. Faktorová analýza sa prakticky používa na a) zistenie vzájomných vzťahov medzi premennými b) pri tvorbe dotazníkov c) pri redukcii veľkého počtu premenných na obmedzený počet faktorov Field (2013, str. 666.)
Predstavme si, že chceme skúmať určité premenné, na ktoré sa nevieme spýtať priamo jednou otázkou, ale len prostredníctvom viacerých iných otázok. K takýmto premenným patria napríklad introverzia, úzkosť, depresia alebo intuícia. V skutočnosti neexistuje len jedna otázka, pomocou ktorej vieme zistiť ako je človek introvertný, úzkostný, alebo ako veľmi je intuitívny. Zvyčajne musíme človeku položiť viacero otázok, niekedy celý dotazník, aby sme si spravili aký taký obraz o tom ako veľmi je, alebo nie je, intuitívny. Konštrukt Intuície je v tomto prípade latentná premenná – faktor, teda premenná, ktorú meriame pomocou viacerých iných otázok v dotazníku, ktoré v tomto prípade nazývame manifestné premenné.
Pri skúmaní konštruktu intuície môžeme použiť dotazník, ktorý vytvorila nemecká výskumníčka Cornelia Betschová (2004). V dotazníku sa snaží identifikovať intuíciu pomocou aj týchto otázok: „Pozorne načúvam svojim najhlbším pocitom“, alebo „Moje pocity hrajú dôležitú úlohu v mojich rozhodnutiach.“ Podobných otázok vytvorila 9, a predpokladala, že tieto otázky dokážu zachytiť konštrukt intuície. Každá otázka sa pýta na intuíciu a jej prejavy trochu iným spôsobom, ale všetky súvisia s intuíciou. Súčasne dotazník obsahuje aj otázky, ktoré majú merať konštrukt uvažovania, deliberácie a tiež pomocou 9tich otázok (manifestných premených). V tomto príklade budeme pracovať s týmto dotazníkom.
Predtým, než sa pustíme do samotnej analýzy tak si ešte vysvetlíme niekoľko dôležitých pojmov. Začneme s tým, že existujú dva typy faktorovej analýzy: exploračná a konfirmačná. Exploračná faktorová analýza bola navrhnutá za účelom objavovať (explore) skryté faktory v rámci skupiny premenných, kedy vopred presne nevieme aké vzťahy máme medzi nimi očakávať. Naopak konfirmačná faktorová analýza bola vytvorená za účelom potvrdiť, overiť už vopred známu, očakávanú existenciu faktorov. Preto pre nové dotazníky, skupiny premenných používame exploračnú faktorovú analýzu, a pre už existujúce, overené a známe používame konfirmačnú faktorovú analýzu. Softvér PSPP umožňuje však počítať len exploračnú faktorovú analýzu. Pri počítaní exploračnej faktorovej analýzy je počet respondentov dôležitý. Field (2013) uvádza, že na každú otázku z dotazníka potrebujeme minimálne 10 až 15 respondentov. Čiže ak má náš dotazník 10 otázok, potom potrebujeme minimálne 100 až 150 respondentov.
K ďalším dôležitým pojmom patrí faktorové zaťaženie, sýtenie alebo faktorový náboj (factor loading), ktorý znamená aká časť variability konkrétnej premennej Xi je vysvetlená konkrétnym faktorom F. Halama (2011) ju opisuje aj ako koreláciu s faktorom, ktorá rovnako ako korelačný koeficient nadobúda hodnoty od -1 po 0 v prípade nepriameho vzťahu alebo od 0 po 1 v prípade priameho vzťahu. Čím sú hodnoty bližšie 1, tým viac premenná sýti daný faktor. Výsledkom exploračnej faktorovej analýzy v programe PSPP je aj faktorová matica, ktorá obsahuje faktorové zaťaženie všetkých premenných (otázok z dotazníka) k jednotlivým faktorom. V matici uvidíme aký vzťah má každá otázka k jednotlivému faktoru, či ho sýti pozitívne, negatívne a ako silno.
Vlastná hodnota (eigenvalue) je podľa Hendla (2009, str. 508) : „číslo, ktoré vo faktorovej analýze udáva pre daný faktor, koľko vysvetľuje variability zo systému premenných, ktoré sledujeme.“ Čím vyššia hodnota, tým faktor viac vysvetľuje z variability premenných. Vlastná hodnota je zvyčajne malé číslo od 0 po približne 10, niekedy i viac (závisí od dát) a nás zaujímajú hodnoty vyššie než 1.
Ak by sme skúmané premenné zobrazili graficky ako body v priestore okolo centrálneho bodu a chceli by sme ich priraďovať k jednotlivým faktorom, tak by sme do priestoru nakreslili dve úsečky, ktoré sa pretínajú v strede. Úsečky by boli vlastne faktory a podľa toho aký typ rotácie úsečiek – faktorov by sme zvolili tak by boli alebo neboli na seba kolmé. Ak by sme ich rotovali avšak vždy by boli na seba kolmé, tak tento typ rotácie sa nazýva ortogonálny. Tu predpokladáme, že sú faktory na sebe nezávislé, vzájomne nekorelujú a sú jedinečné. Alebo by mohli zvierať akýkoľvek iný uhol a boli by teda vzájomne na seba šikmé. Rotácia faktorov sa používa aj v programe PSPP, ktorý nám ponúka štyri typy rotácie:
- Žiadnu (None)
- Varimax je kolmý (ortogonálny) typ rotácie. V tomto prípade program rotuje osi, avšak vždy sú jednotlivé osi na seba kolmé. Súčasne každá premenná sýti len jeden faktor, teda minimalizuje počet premenných, ktoré majú vysoký náboj. Tento typ rotácie je v programe prednastavený, pretože sa najľahšie interpretuje a má aj najširšie možnosti aplikácie.
- Quartimax minimalizuje počet faktorov a je taktiež kolmý typ rotácie.
- Equimax je kombináciou hore uvedených. Snaží sa vybrať minimálny počet faktorov a súčasne každá premenná sýti len jeden faktor. Je to tiež ortogonálny typ rotácie.
Sutinový graf (scree plot) je graf zložený z vlastných hodnôt (eigenvalues), ktoré sú na Y-novej osi a faktorov na X-ovej osi zoradených od najvyšších po najnižšie. Graf vždy klesá, a pri interpretácii je dôležitý jeho tvar. Prudký pokles krivky grafu je ideálny, nakoľko znamená, že máme málo faktorov s vysokými vlastnými hodnotami (eigenvalues). Teda manifestné premenné (otázky z dotazníka) dobre sýtia jednotlivé faktory, ktorých nie je veľa.
Podrobnejšie a v súvislostiach si tieto pojmy vysvetlíme na riešení a interpretácii nasledovného príkladu.
Zadanie úlohy:
Pomocou exploračnej faktorovej analýzy preskúmajte nemecký dotazník dotazník PID ( Preference for Intuition and Deliberation, Betsch, 2004) na vzorke slovenskej populácie. Príklad č. 1 – Faktorová analýza. Dotazník má 18 otázok a polovica z nich by mala sýtiť latentnú premennú intuíciu a druhá polovica otázok ( inými slovami aj manifestných premenných) latentnú premennú nazvanú deliberácia, teda sklon k uvažovaniu a racionalite. V našom príklade vidíme, že každá z otázok je označená na základe nasledovného princípu: PID_1d, kde 1d znamená, že ide o prvú otázku zo subškály deliberácia. Teda tie, ktoré súvisia s deliberáciou sú označené PID_d číslo otázky, napr. PID_d1, PID_d5 atď. A podobne tie, ktoré súvisia s intuíciou sú označené napr. PID_i1, PID_i2 atď. U výsledkov predpokladáme, že nájdeme dva dominantné faktory, ktoré budú nezávislé a otázky zo subškály deliberácia budú sýtiť 1 faktor a otázky zo subškály intuícia, uvažovanie budú sýtiť druhý faktor.
Pred samotnou faktorovou analýzou ešte poznamenávam nasledovné. Ak by sme skúmali už existujúci a v našej populácii overený dotazník mali by sme použiť konfirmačnú faktorovú analýzu. My však skúmame dotazník na Slovensku zatiaľ neuvedený, ktorého pôvodná vzorka bola zložená z nemeckých občanov. Preto môžeme argumentovať, že objavujeme (exlore) aké faktory dotazník bude mať pre slovenskú populáciu.
Riešenie:
Otvoríme si súbor s názvom Príklad č. 1 – Faktorová analýza. V ponuke Analyzovať (Analyze) si vyberieme Exploračnú faktorovú analýzu (Factor Analysis…). Najprv presunieme všetky otázky z dotazníka pre intuíciu označené PID_i1 až i9 ako aj pre deliberáciu označené PID_d1 až PID_d9, teda spolu 18 premenných, vpravo do poľa Premenné (Variables). Ďalej, po otvorení dialógového okna nám program v spodnej časti menu ponúka dve možnosti: Extrakciu (Extraction) a Rotácie (Rotation). Musíme vyplniť obidve a tak si klikneme najprv na Extrakciu a budeme postupovať nasledovne. Pri našej analýze vyberieme metódu: Analýzu hlavných komponentov (Principal component analysis), ďalej zaškrtneme Korelačnú maticu (Corelation matrix) a Sutinový graf (Scree plot). A dáme vyextrahovať vlastné hodnoty väčšie ako 1. Počet faktorov nebudeme limitovať. Maximálny počet iterácií nenastavujeme. V prípade, že softvér nebude chcieť spustiť analýzu, potom môžeme pridať znamienkom + o 1 iteráciu viac, čo zvyčajne už analýzu spustí. Na záver klikneme na Pokračovať(Continue).
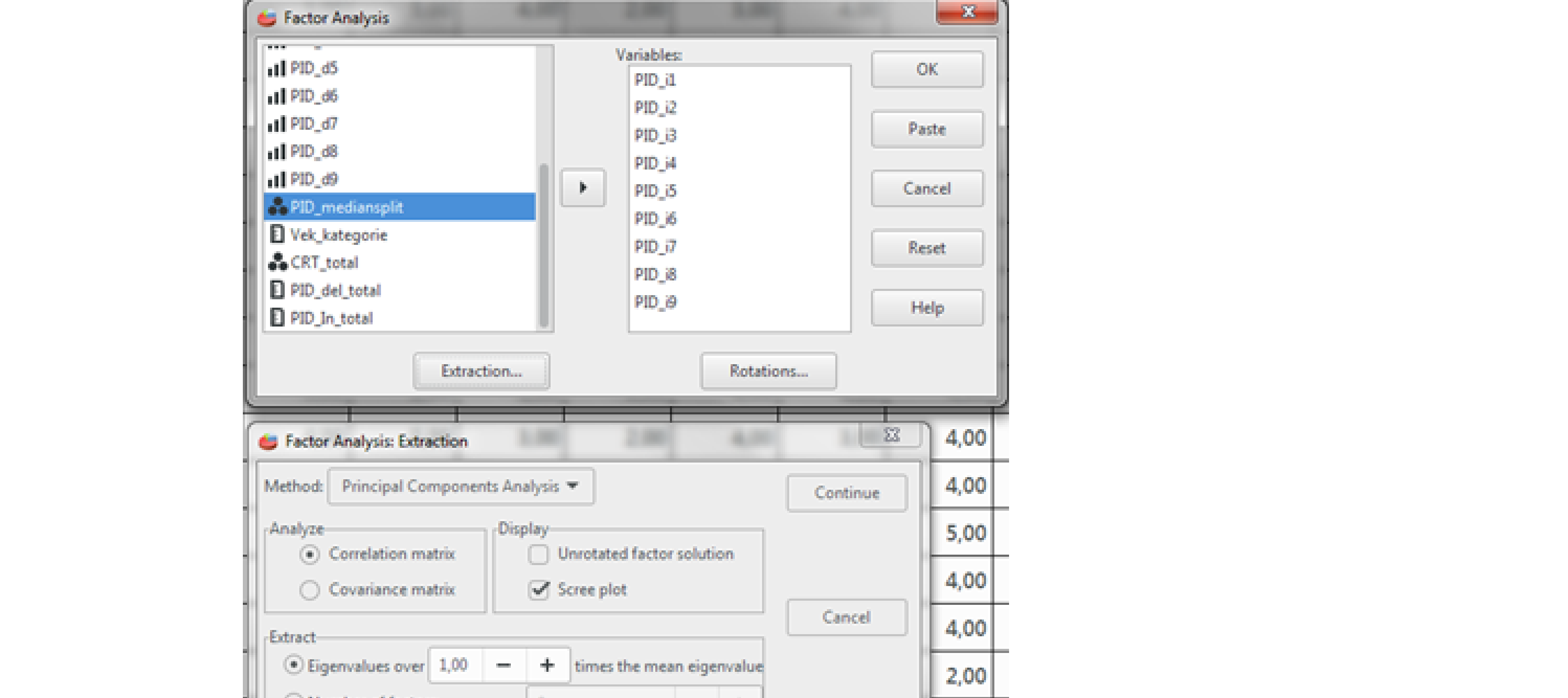
Obr. 1 Dialógové okno Extrakcia a Rotácia faktorov
Potom klikneme na dialógové okno Rotácie (Rotations) nám ponúka tri metódy rotácie. Vyberieme Varimax metóda (kolmý typ rotácie), ktorá je v programe. Následne klikneme Pokračovať (Continue) a spustíme celú analýzu kliknutím Ok.
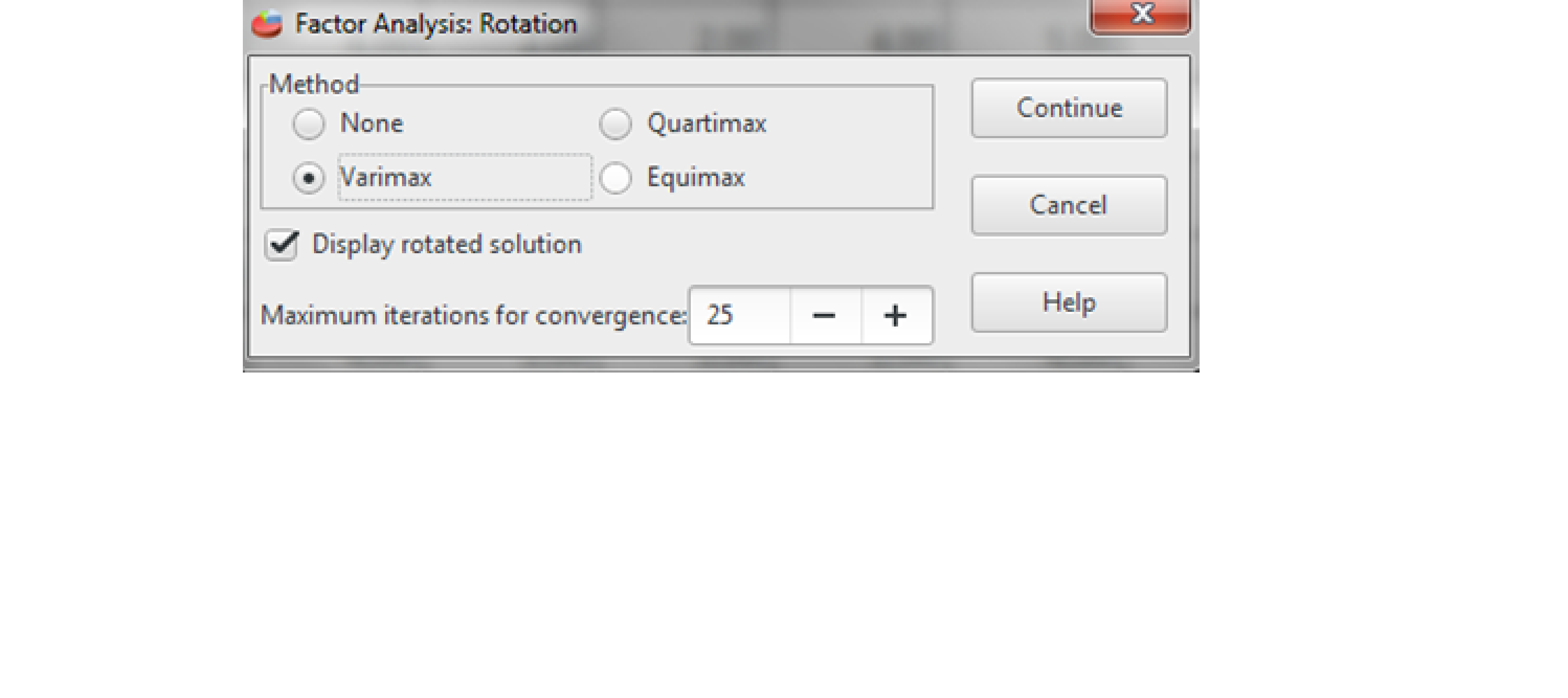
Obr. 2 Dialógové okno rotácie faktorov
Výsledky:
Výsledkom faktorovej analýzy je viacero tabuliek a Sutinový graf (Scree plot), ktoré si opíšeme podrobnejšie. Začneme grafickou interpretáciou sutinového grafu. V Sutinovom grafe (Scree plot) vidíme (obr. 1), že existujú minimálne dva dominantné faktory, ktorých vlastná hodnota (eigenvalue) je vyššia než 1. Podľa predpokladov dotazník má merať 2 faktory: intuíciu a uvažovanie, čiže prvotné grafické výsledky zbežne potvrdzujú naše predpoklady. No na robenie štatistických úsudkov potrebujeme pracovať s exaktnými číslami, ktoré sú uvedené v tabuľkách na obrázku dole.
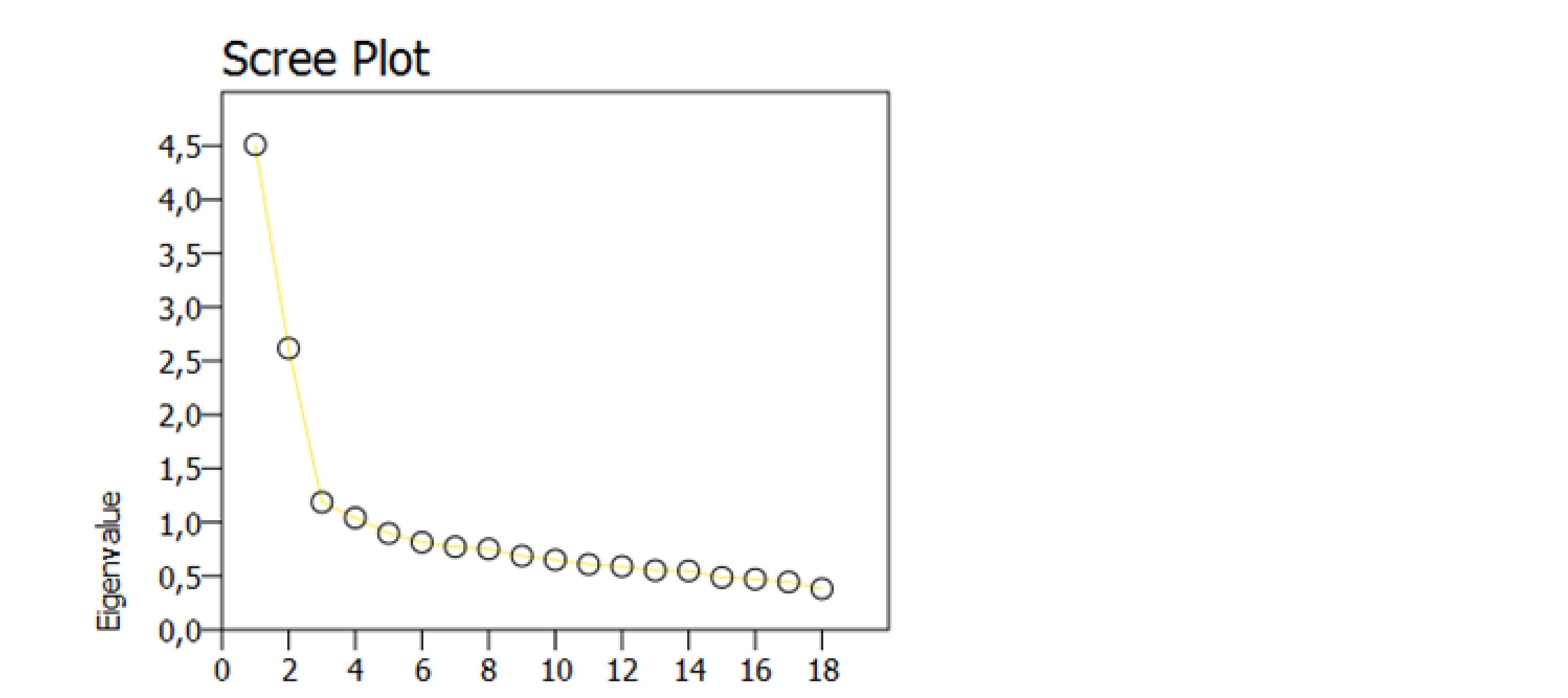
Obr. 3 Sutinový graf (Scree plot)
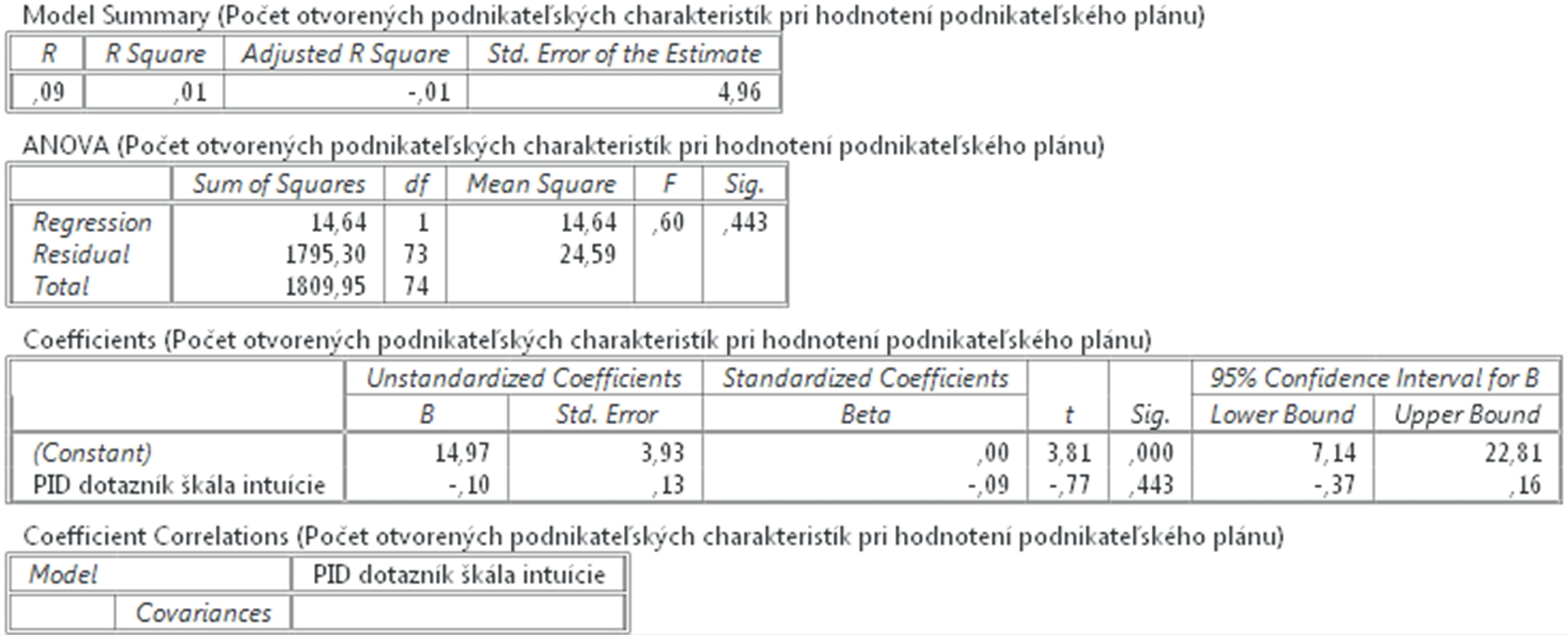
V nasledovnej tabuľke podrobnejšie opíšeme grafické zobrazenie faktorov v sutinovom grafe. V prvom stĺpci sú uvedené všetky faktory. V druhom je Vlastná hodnota jednotlivých faktorov (Eigenvalues) v stĺpci Total. V druhom stĺpci je uvedené percento variability, ktorú vysvetľuje konkrétny faktor. A v poslednom stĺpci je uvedené kumulatívne percento. Zaujímajú nás faktory, u ktorých je Vlastná hodnota (Eigenvalues) vyššia než 1 v našej tabuľke vidíme, že 4 faktory majú vlastnú hodnotu vyššiu než 1. Prvý, najvýznamnejší faktor vysvetľuje 25,05 % variability, druhý 14,54% a spolu 39,59%. To nie je zvlášť veľa nakoľko dotazník mal merať len 2 faktory a my sme zistili ďalšie dva s vlastnou hodnotou väčšou ako 1 a tiež Celkové percento variability (Cumulative %) vysvetlené týmito faktormi je pomerne nízke.
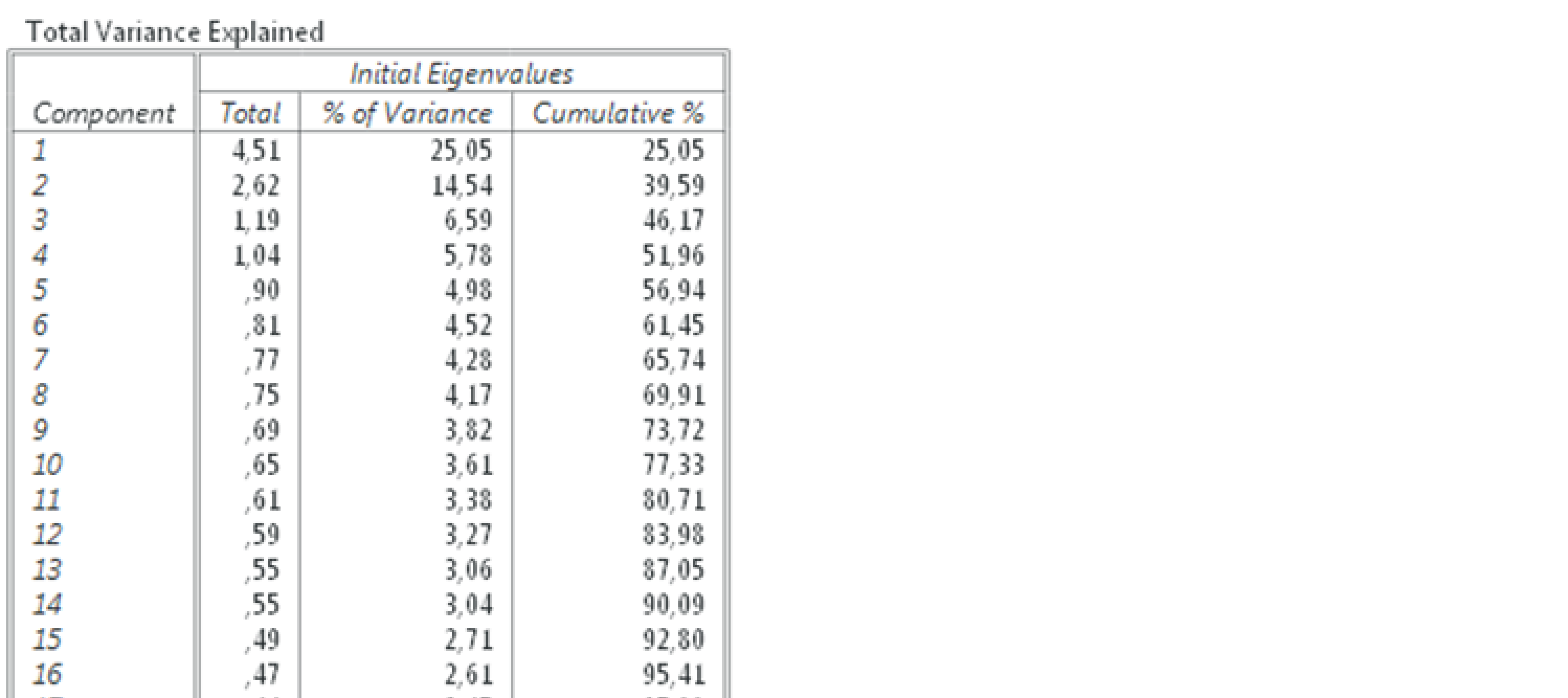
Obr. 3 Identifikované faktory, vlastné hodnoty (eigenvalues) a percentá vysvetlenej variability
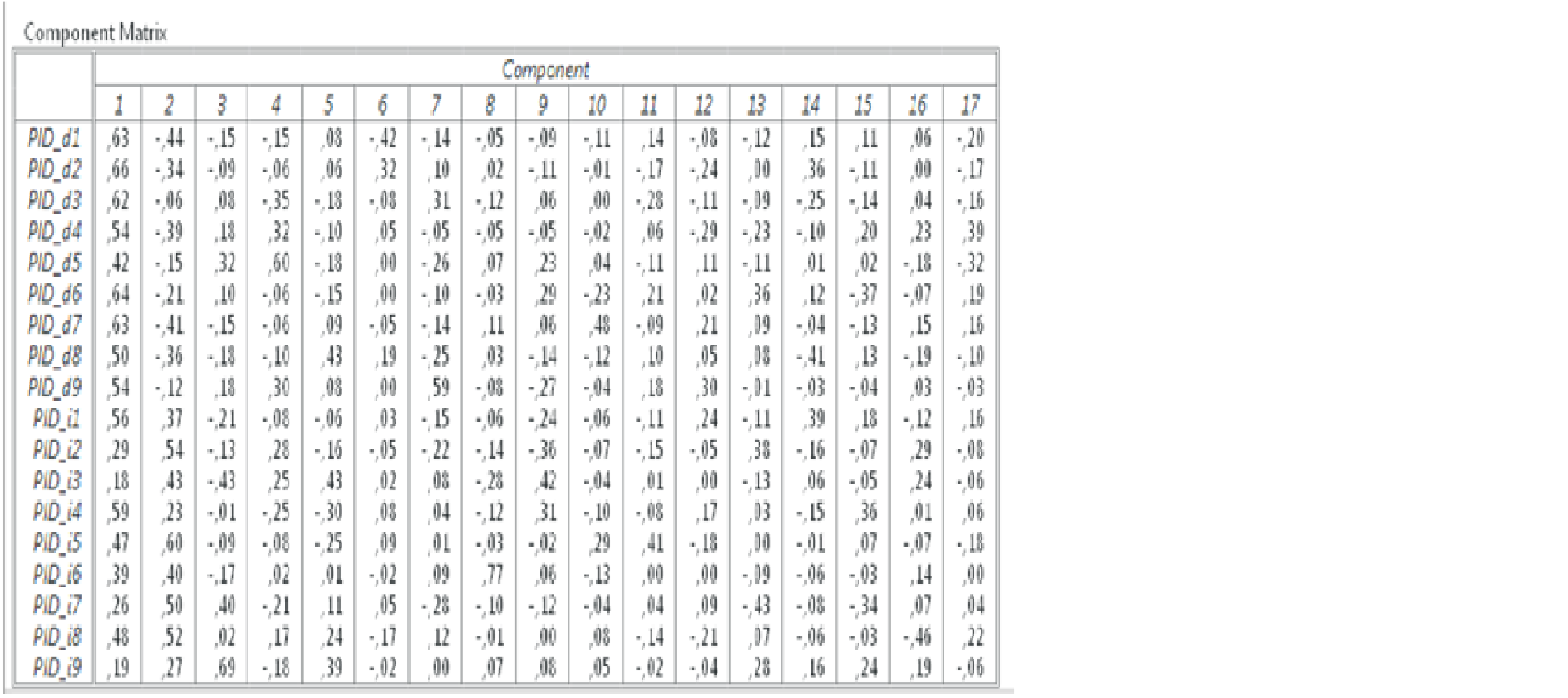
Obr. 4 Faktorová matica pre všetky faktory a všetky otázky z dotazníka PID
Na obrázku č. 4 je uvedený faktorový náboj, sýtenie pre každú otázku z dotazníka. V prvom riadku je otázka PID_d1, čiže zo škály deliberácia, uvažovanie. Táto otázka má pre prvý najsilnejší faktor sýtenie 0,63 a pre druhý faktor záporné sýtenie rovné -0,44. Rovnako ostatné otázky zo škály uvažovanie majú pre prvý faktor pozitívne sýtenie. Čiže všetky otázky zo škály deliberácia pozitívne korelujú s faktorom č. 1, a zároveň negatívne korelujú s faktorom č. 2. Preto prvý najsilnejší faktor (č. 1) môžeme nazvať uvažovanie – deliberácia.
Veľmi problematické sú otázky zo subškály intuícia PIDi_1 až PIDi_9, ktoré pozitívne sýtia aj prvý faktor (č. 1) aj druhý faktor (č.2). Jednotlivé otázky zo škály intuícia už z etablovaného dotazníka PID majú mať pozitívny vzťah k intuícii a negatívny k deliberácii. A nie pozitívny k obidvom. Napr. otázka PIDi_1 koreluje pozitívne s faktorom deliberácia 0,56 (mala by korelovať negatívne) a tiež pozitívne 0,37 s druhým faktorom (intuícia). Podľa očakávaní a predpokladov by mali byť všetky otázky z intuície rozhodne v negatívnom vzťahu k prvému faktoru (deliberácia), teda mali by byť záporné a v pozitívnom k druhému faktoru (intuícia). Pretože takto tieto otázky merajú aj deliberáciu a nie len intuíciu, ako by mali.
Interpretácia:
Dotazník PID bol konštruovaný ako dvojfaktorový dotazník, ktorý mal merať Intuíciu a Deliberáciu, Uvažovanie (Racionalitu). Preto sa očakáva, že každá otázka súvisiaca s Intuíciou bude vysoko sýtiť faktor intuícia a každá otázka súvisiaca s deliberáciou zas faktor deliberácia. Zároveň sa však očakáva aj že každá otázka v pozitívnom vzťahu s faktorom č. 1 – deliberácia bude v negatívnom vzťahu k faktoru č. 2 – intuícia. To sa potvrdilo. Problémom však je že otázky z intuície, ktoré by mali sýtiť pozitívne len faktor č. 2 (intuíciu) pozitívne sýtia aj faktor č. 1(deliberáciu). Teda otázky z intuície „merajú“ aj uvažovanie, deliberáciu. To je veľmi problematické pretože otázka, ktorá má merať intuíciu nemôže súčasne merať aj uvažovanie (deliberáciu). Na základe výsledkov konštatujeme, že otázky zo škály intuícia z dotazníka PID sýtia pozitívne obidva faktory a nie sú jednoznačne priradené len k intuícii ale aj k deliberácii.
Uvádzanie výsledkov:
Na analýzu vnútornej štruktúry dotazníka PID (Betsch, 2004) slovenskom prostredí bola zvolená exploračná faktorová analýza, pomocou metódy hlavných komponentov (principal axis factoring), ortogonálna rotácia Varimax. V skúmanej vzroke sme identifikovali 4 faktory, ktorých vlastná hodnota (Eigenvalue) bola vyššia ako 1. Prvý faktor vysvetľoval 25,05 % variability a druhý 14,54 %, spolu vysvetľovali spolu 39,59 %, tretí faktor 6,59% a štvrtý 5,78%.
Všetky otázky zo subškály Deliberácia, ktoré mali sýtiť latentný faktor Deliberáciu boli v pozitívnom vzťahu s týmto faktorom a faktorové zaťaženie sa pohybovalo od 0,42 pre PID_d5 po 0,66 pre PID_d2. Pri latentnej premennej Intuícia bolo faktorové zaťaženie všetkých otázok merajúcich intuíciu bolo v pozitívnom vzťahu a pohybovalo sa od 0,19 pre PID_i9 po 054 pre PID_i9. Avšak súčasne všetky otázky zo subškály Intuícia taktiež pozitívne sýtili faktor deliberácia, čo je priamom rozpore s predpokladmi.
Spracoval Róbert Hanák, 10. Novembra 2015