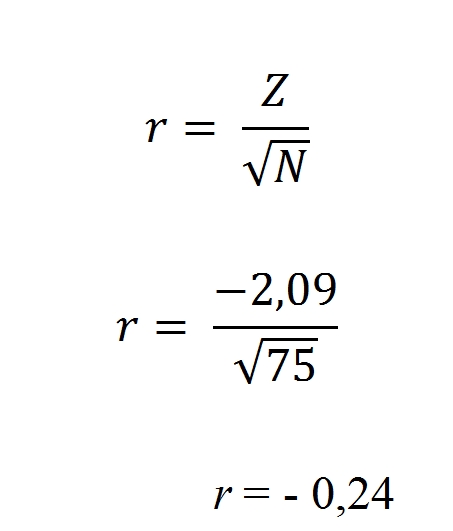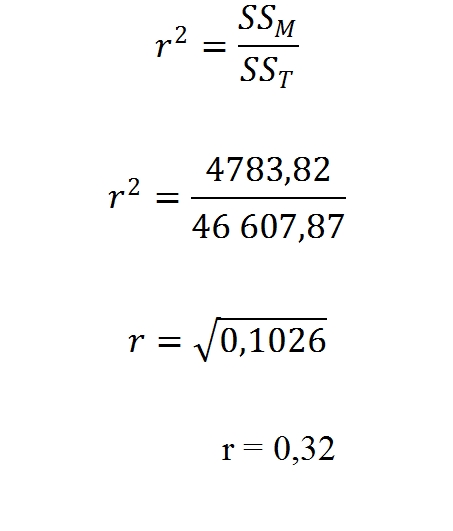Analýza závislostí u ordinálnych premenných
Ordinálne premenné sú poradové premenné a v mnohých prípadoch ide o výroky v dotazníku ako napríklad: veľmi súhlasím, súhlasím, čiastočne súhlasím, čiastočne nesúhlasím, nesúhlasím a veľmi nesúhlasím. Program PSPP ponúka viacero štatistických metód na výpočet vzájomných vzťahov medzi ordinálnymi premennými, ktoré sú založené na porovnávaní hodnôt premenných medzi jednotkami v súbore. Konkrétne porovnávanie hodnôt medzi jednotlivými respondentami, kde sa porovnáva respondent 1 s respondentom 2, atď. Pri tomto porovnávaní sa hľadá vzájomná zhoda/nezhoda.
Goodmanova – Kruskalova gamma (Goodman and Kruskal’s gamma – G)
Softvér PSPP používa skratku pre tento koeficient GAMMA a je založená na porovnávaní hodnôt premennej v prípade po sebe nasledujúcich jednotiek v súbore. Nadobúda hodnoty od – 1 po 0 alebo od 0 po 1.
Kenadallovo tau b (Kendall’s tau b – τ)
Počíta sa na rovnakom princípe ako hore uvedená gamma, no z menovateľa nevylučuje páry so spriahnutým poradím. PSPP používa skratku pre tento koeficient BTAU. Výsledok u obidvoch tau nadobúda hodnoty v intervale -1 až 0, resp. 0 až 1.
Kenadallovo tau c (Kendall’s tau c – τ)
Princíp výpočtu je rovnaký ako v prípade Kenadallovo tau b a v menovateli je aj počet jednotiek vo výbere. Výsledok u obidvoch tau nadobúda hodnoty v intervale -1 až 0, resp. 0 až 1. PSPP používa skratku pre tento koeficient CTAU.
Spearmanovo rho (Spearman correlation)
Je korelačný koeficient, ktorý je založený na poradí premenných. Na rozdiel od Pearsonovho koeficientu ho môžeme aplikovať aj na nie normálne rozložené (distribuované) dáta a dokáže zachytiť iný než len lineárny vzťah medzi premenenými. Zároveň nie je tak citlivý na extrémne hodnoty (outliers) ako Pearsonov korelačný koeficient. PSPP používa skratku pre tento koeficient CORR a nadobúda hodnoty od -1 po 0 v prípade nepriamej závislosti a od 0 po 1 v prípade priamej závislosti.
Príklad č. 2. Študenti body a pamäť
Študenti boli požiadaní aby posúdili kvalitu podnikateľského zámeru opísanú v podnikateľskom pláne a pridelili mu body od 0 po 10. Podnikateľský plán bol opísaný 25 charakteristikami ako cena, súčasná konkurencia, vzhľad atď. avšak študenti okrem nadpisu obsah vlastností hneď nevideli, ale mohli si na ne kliknúť a potom sa im objavil obsah. Takmer všetky charakteristiky boli opísané pozitívne, avšak v 3 najdôležitejších charakteristikách ( ako napr. ziskovosť, alebo doba návratnosti ) z 25 boli slabé miesta tohto plánu. Skúsený manažér by preto podnikateľský plán hodnotil negatívne. Zaujíma nás či počet otvorených podnikateľských charakteristík súvisí s celkovým hodnotením podnikateľského plánu. Očakávame, že čím viac podnikateľských charakteristík si študent otvoril a videl ich obsah, tým realistickejší obraz o pláne získal a odhalil jeho slabé miesta, a preto ho hodnotil nie príliš pozitívne. Hypotézy si stanovíme nasledovne:
H1 Počet otvorených podnikateľských charakteristík v business pláne je v negatívnom vzťahu s celkovým hodnotením podnikateľského plánu.
H0 Počet otvorených podnikateľských charakteristík v business pláne nesúvisí s celkovým hodnotením podnikateľského plánu.
Riešenie:
To akú štatistickú metódu použijeme na overenie vzájomných vzťahov v tomto prípade závisí od ako sú dáta rozložené (normálne rozloženie alebo nie normálne rozloženie našich dát). Parametrický test štatistickej významnosti robíme pomocou Pearsonovho korelačného koeficientu a používame ho len vtedy ak majú premenné normálne rozdelenie. Ten je uvedený v programe PSPP v menu Analyzovať(Analyze) ako Bivariate Correlation. V prípade, ak rozdelenie našich dát nie je normálne, alebo ho nevieme overiť, musíme používať neparametrické testy korelačného koeficientu (Pacáková, 2015, str. 220), ktoré sú uvedené vyššie. Čiže postup práce bude nasledovný:
- krok – Overenie normality rozloženia dát
- krok – Podľa toho ako sú dáta rozložené aplikujeme nasledovnú metódu: A) ak sú dáta rozložené normálne použijeme Pearsonov korelačný koeficient. B) ak dáta nie sú rozložené normálne použijeme Kendallovo tau. Môžeme použiť aj Spearmanovo rho a vysoký počet kategórií u premennej Počet otvorených charakteristík nám umožňuje teoreticky uvažovať s touto premennou ako s intervalovou a potom môžeme použiť aj koeficient Eta.
Postup:
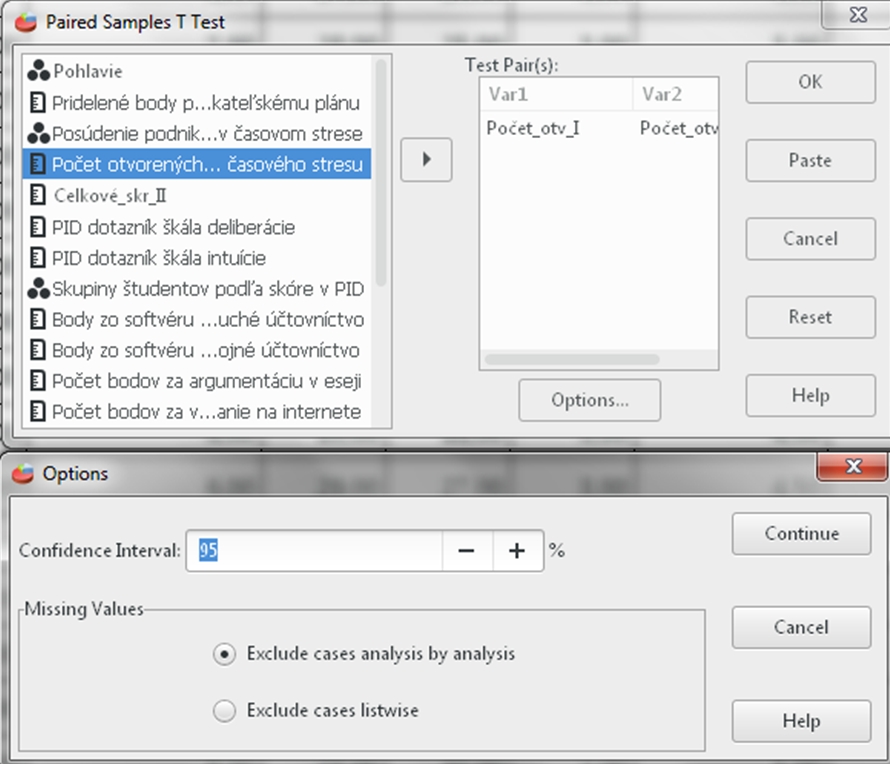
- Krok: Overenie normality rozloženia dát.
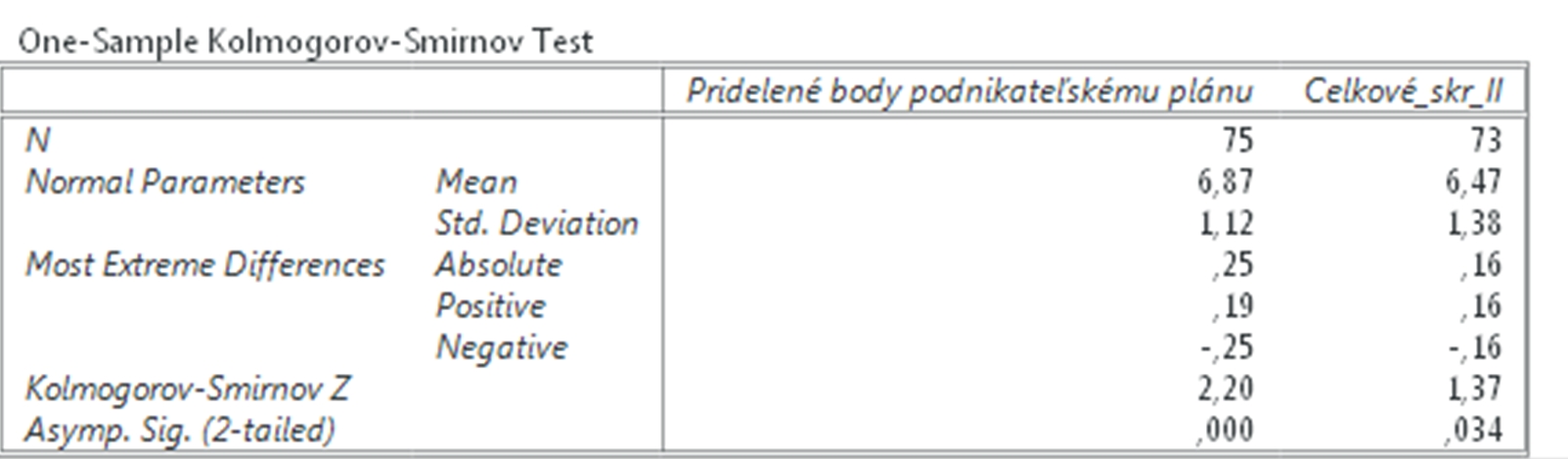
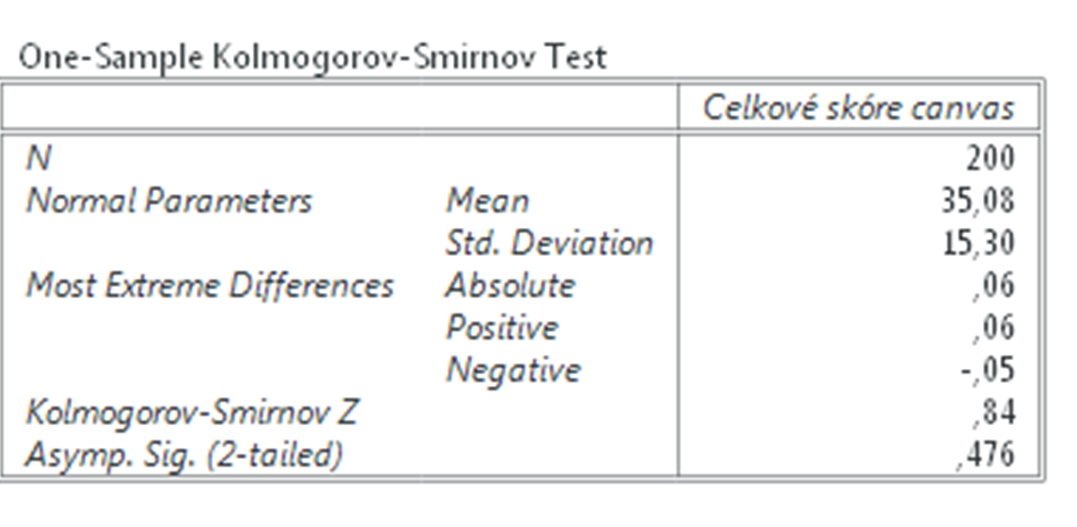
Na overenie normality rozoloženia dát použijeme Kolmogorov Smirnovov test, ktorý sa nachádza v neparametrických štatistikách. Klikneme na Analyzovať (Analyze), potom na Neparametrické štatistiky (NonParametric Statistics) a vyberieme 1 výberový K – S (1Sample K – S), čo je skratka pre Kolmogorov – Smirnovov test. Následne vyberieme premenné Počet_otv_II (čo je počet otvorených podnikateľských charakteristík bez časového stresu) a Celkové_skr_II (celkové skóre, ktoré študenti pridelili podnikateľskému plánu od 0 po 10) a dole zvolíme Test Distribúcie (Test Distribution). V našom prípade vyberieme Normálne rozloženie (Normal). Na záver klikneme OK.
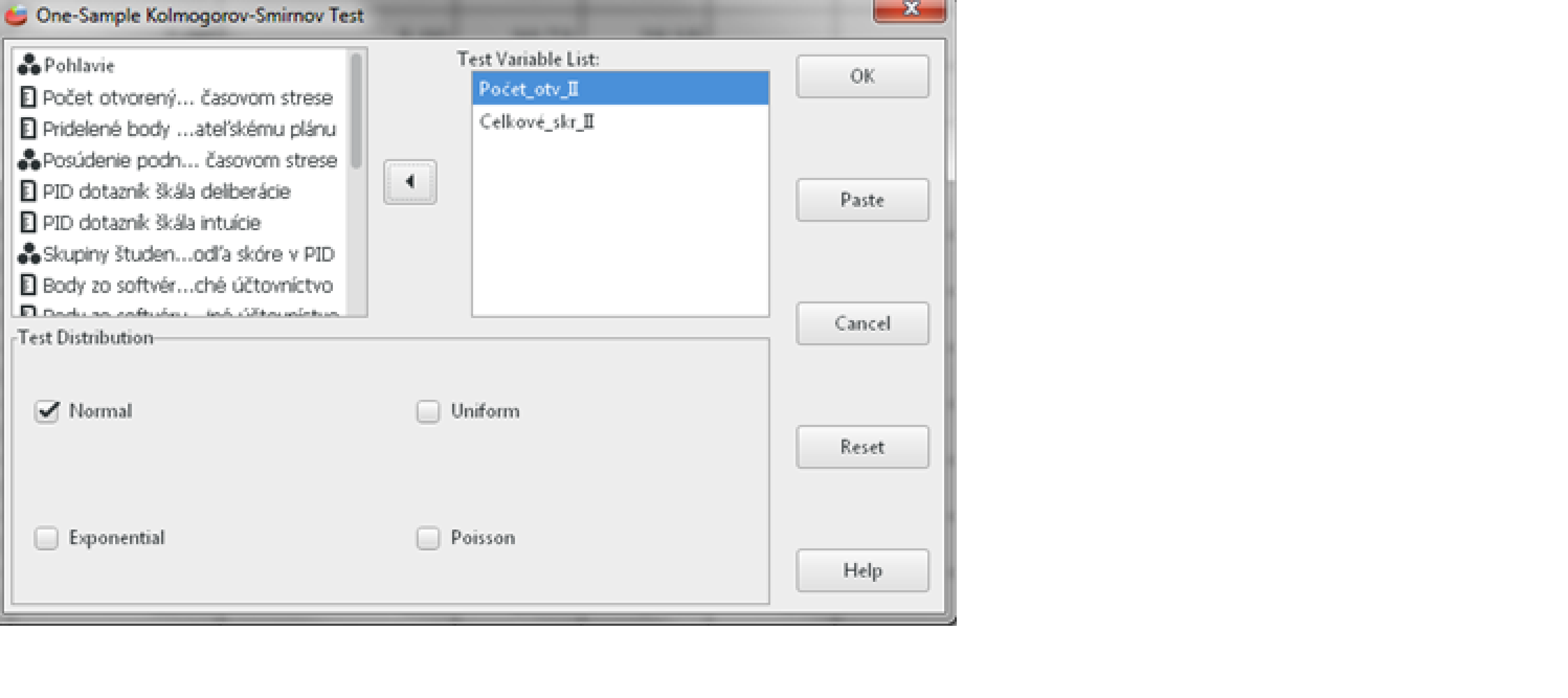
Obr. 1 Sprievodca overením normality rozloženia dát pomoc Kolmogorovho-Smirnovho testu
Výsledkom je tabuľka s opisnými charakteristikami a s výsledkami Kolmogorovho-Smirnovho testu uvedenými v posledných dvoch riadkoch. Čiže ak je hladina významnosti v poslednom riadku nižšia než 0,05, potom sú výsledky nie normálneho rozloženia štatisticky významné. Čiže ak sú nižšie než 0,05, potom dáta nie sú rozložené normálne a nemôžeme použiť Pearsonov korelačný koeficient. Ako vidíme pri premennej Celkové skóre, tu je koeficient nižší než 0,05, teda hodnoty premennej nie sú rozložené normálne. Hoci pri premennej Počet otvorených podnikateľských charakteristík je mierne nad 0,05, stále je veľmi blízko a preto musíme použiť neparametrické testy na meranie vzájomnej závislosti premenných.
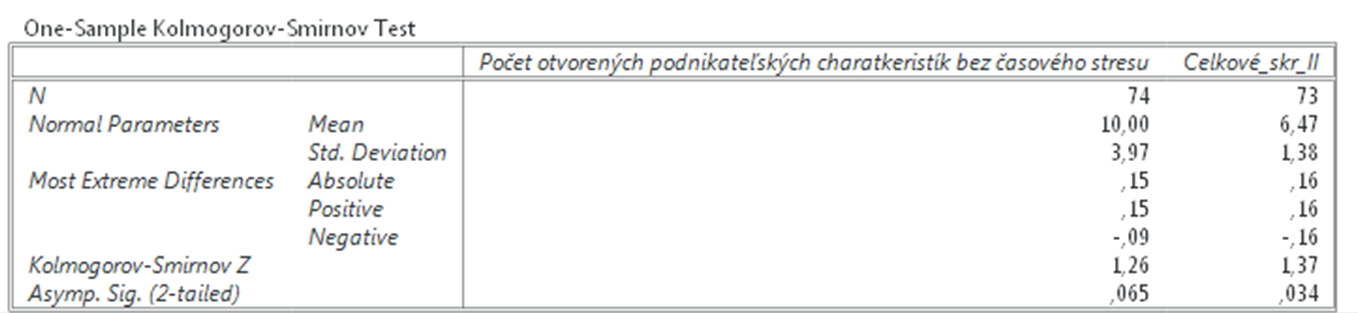
Obr. 2. Výsledok testu Kolmogorov-Smirnov Test normality rozloženia dát
2 krok: Výber vhodného testu na skúmanie vzťahov medzi premennými.
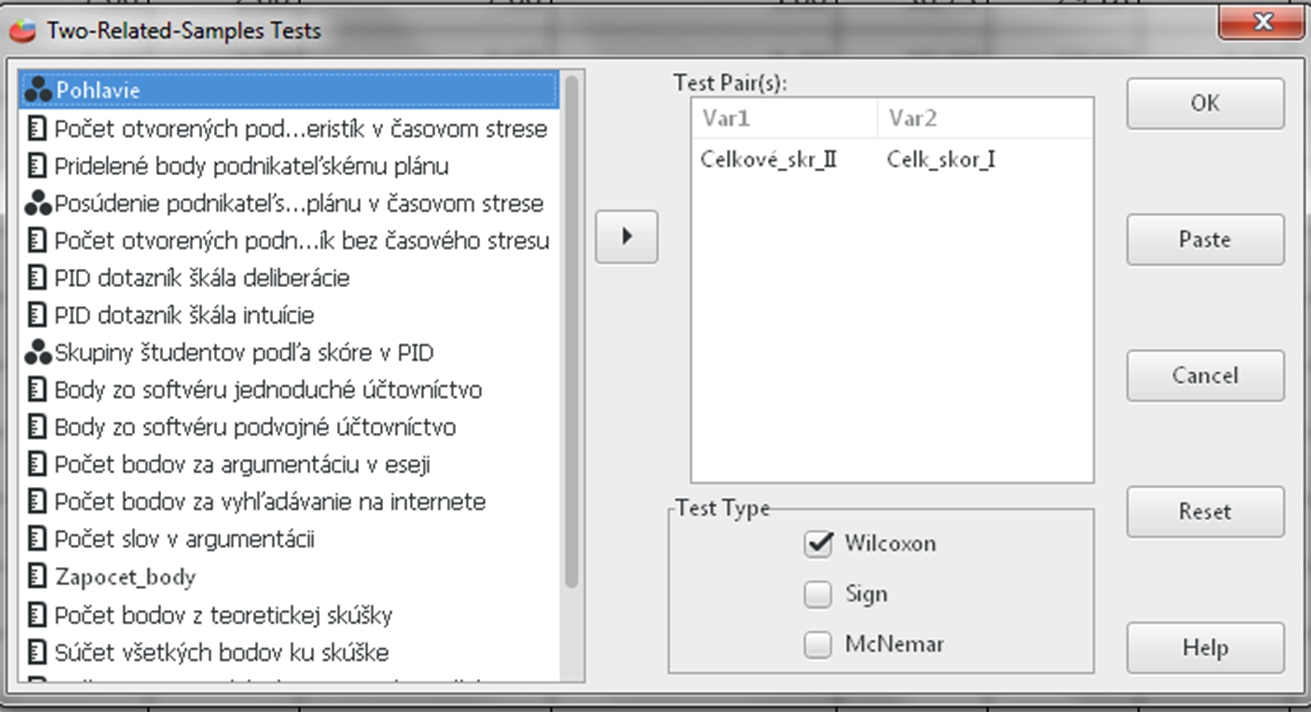
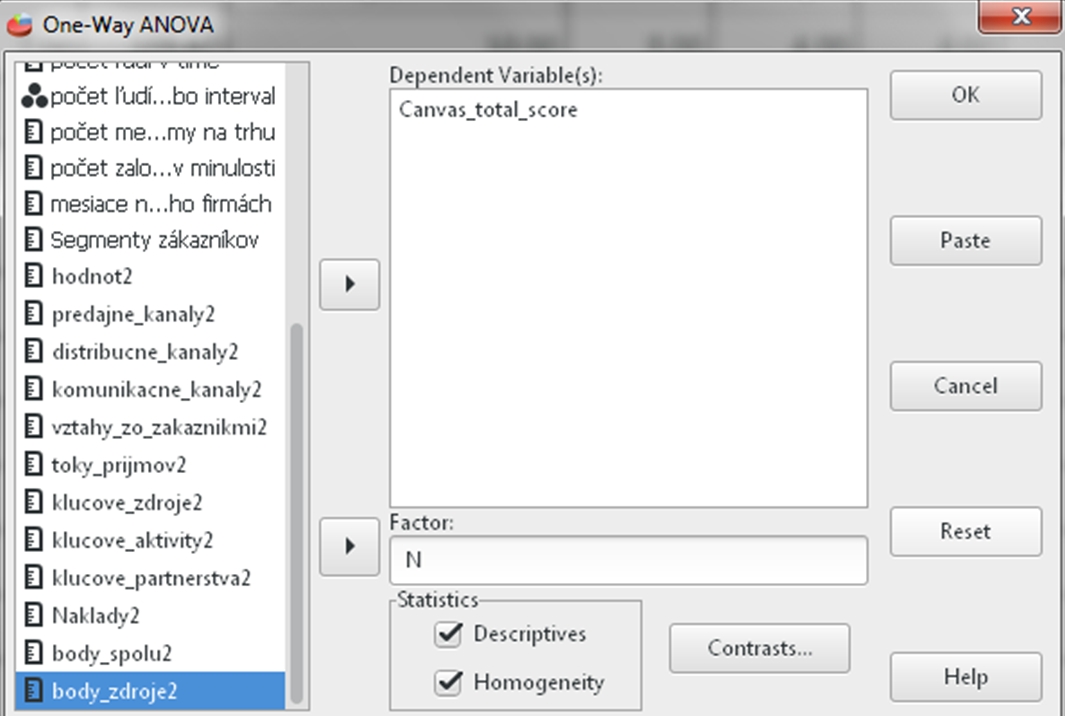
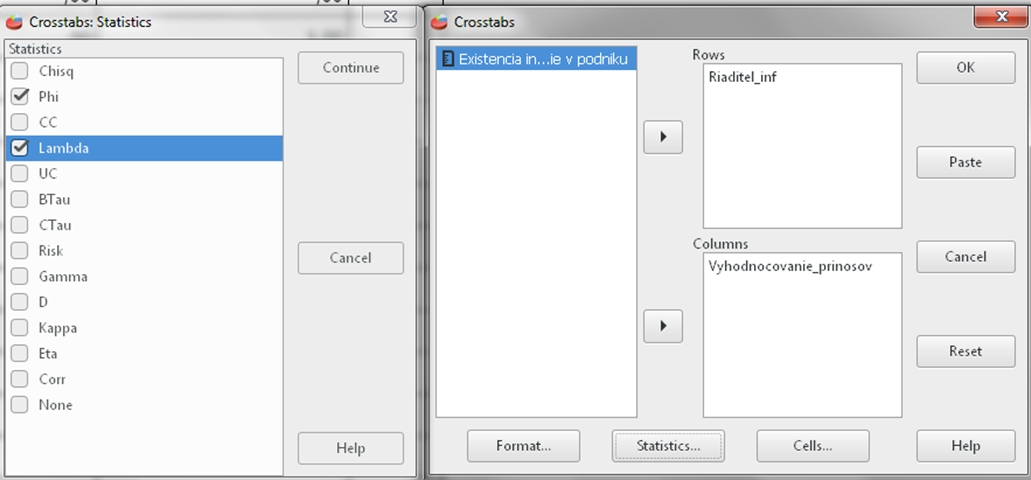
Na základe výsledkov Kolmogorovho-Smirnovho testu vieme, že dáta nie sú rozložené normálne, a preto nemôžeme použiť Pearsonovu koreláciu. Použijeme Kenallovo tau. To sa nachádza v Analyzovať (Analyze), potom klikneme na Opisné štatistiky (Descriptive Statistics) a vyberieme Krížové tabuľky (Crosstabs). Vyberieme nasledovné dve premenné: Počet_otv_II (čo je počet otvorených podnikateľských charakteristík bez časového stresu) a Celkové_skr_II (celkové skóre, ktoré študenti pridelili podnikateľskému plánu od 0 po 10) V dialógovom okne si dole otvoríme Štatistiky (Statistics) a vyberieme si, konkrétnu štatistickú metódu, ktorú chceme spustiť. V našom prípade je to Kendallovo Tau b aj c, označené ako BTau a CTau, koeficent Eta a Spearmanovu koreláciu označenú Corr. Následne klineme OK.
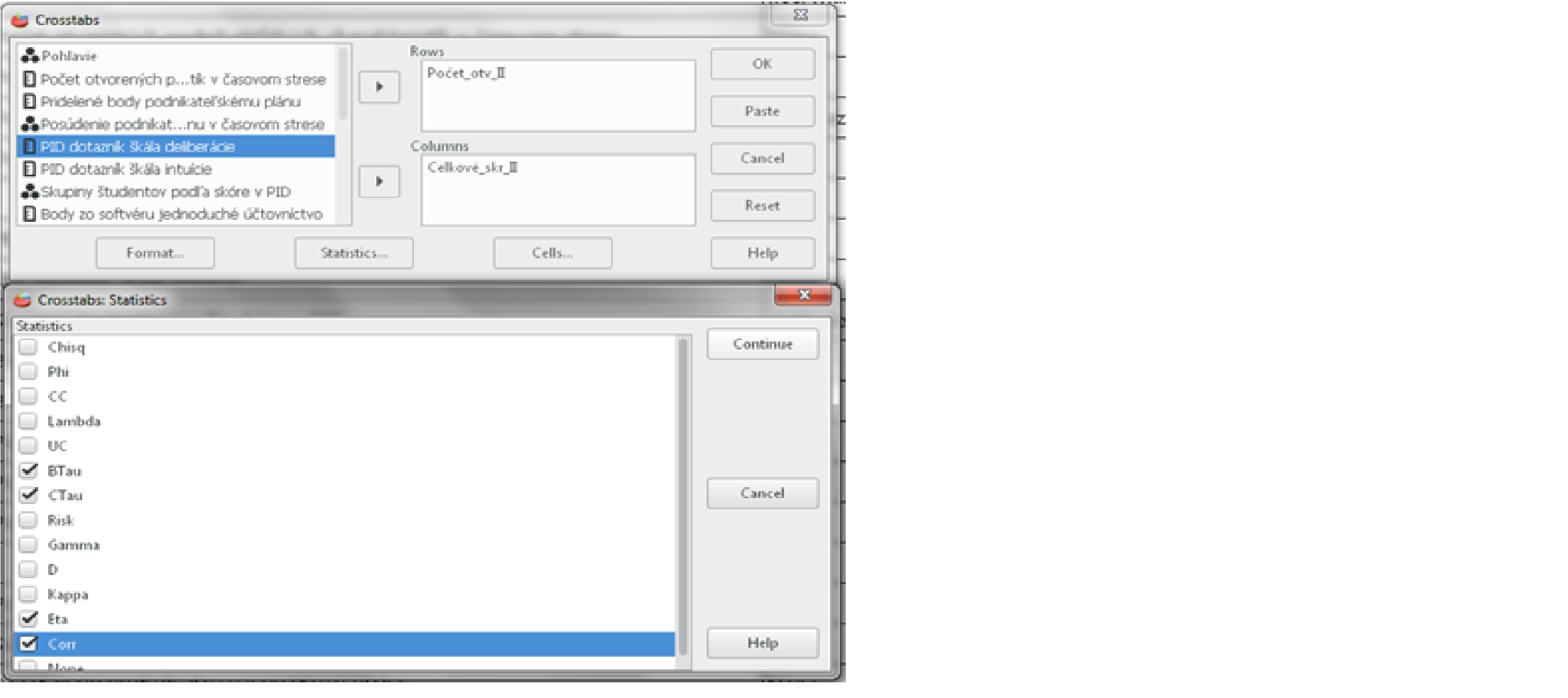
Obr. 3. Sprievodca Spearmannovou koreláciou a Kendallovým tau a koeficientom Eta.
Výsledok a interpretácia:
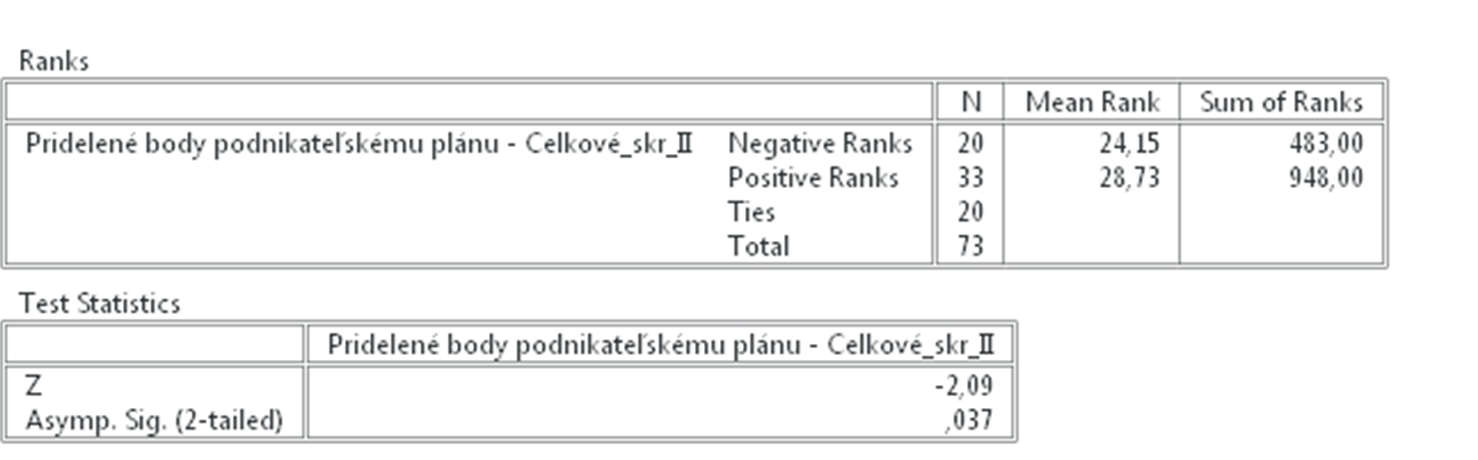
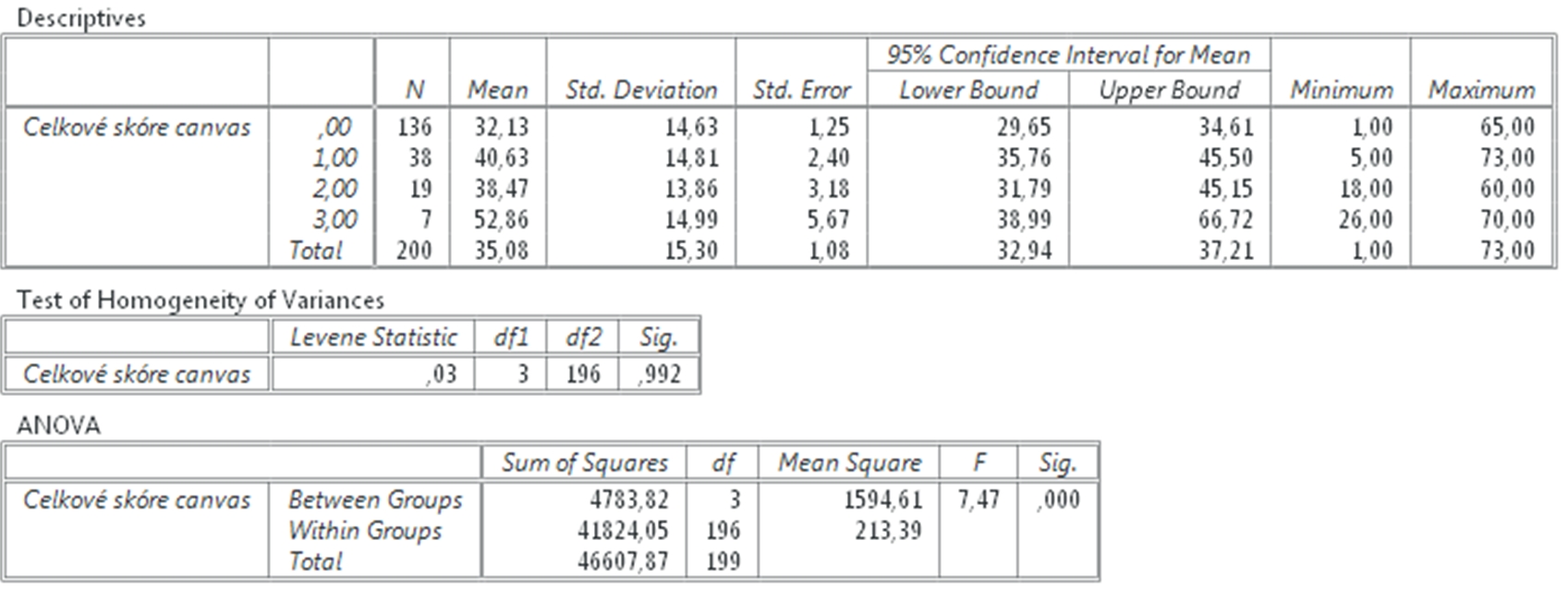
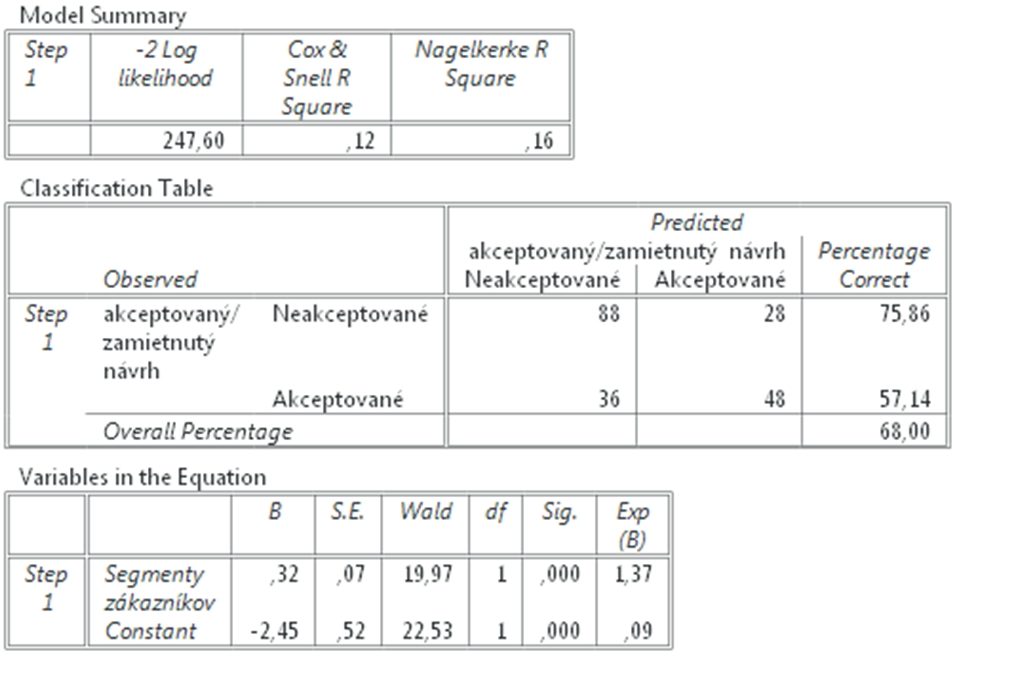
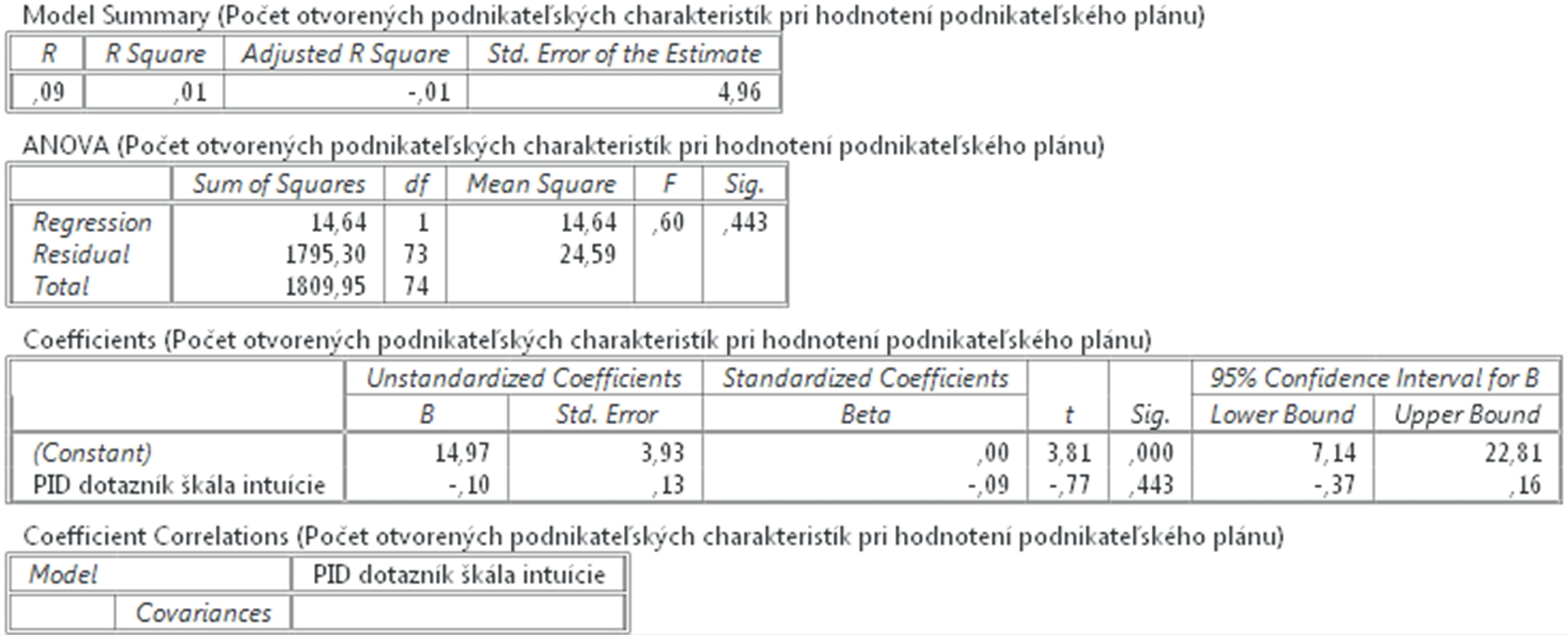
Výsledkom sú dve tabuľky, ktorých obsah si v krátkosti opíšeme. Hodnoty Kenallovho tau – b a tau-c sú 0,18 a 0,17, Spearmanova korelácia je 0,23 a program PSPP zobrazil aj výsledky Pearsonovej korelácie = 0,2. Výsledky sa odlišujú nakoľko každá štatistická metóda je založená na inom vzorci, avšak hodnoty sú podobné. Ak si máme vybrať, ktoré výsledky budeme uvádzať, potom použijeme pravidlo, ktoré hovorí, že reportujeme tú metódu, ktorej výsledok je najnižší.
Súčasne môžeme konštatovať, že nie sú vysoké (bližšie k 0 než 1) a teda vzájomný vzťah síce existuje, ale nie je veľmi silný. Koeficienty sú všetky pozitívne, čo znamená, že čím viac si študent podnikateľských charakteristík otvoril, tým vyššie skóre podnikateľskému plánu dal. Čo sa týka koeficientu Eta ak by sme uvažovali o celkovom skóre podnikateľského plánu ako závislom na počte otvorených podnikateľských charakteristík, potom je koeficient Eta = 0,42, čo je už pomerne silný vzájomný vzťah. Ak umocníme koeficient eta na druhú mocninu, tak dostaneme 17,64% a môžeme konštatovať že 17,64% variability z celkového skóre pre podnikateľský plán závisí od počtu otvorených podnikateľských charakteristík. V hypotéze H1 sme tvrdili, že premenné budú v negatívnom vzájomnom vzťahu, čo sa nám nepotvrdilo, a preto hypotézu H1 zamietame a prijímame hypotézu H0.

Obr. 4. Výsledok Kenallovho tau, Spearmanovej korelácie a koeficientu Eta.
Reportovanie výsledkov:
Počet otvorených podnikateľských charakteristík bez časového stresu súvisí s celkovým hodnotením podniku len mierne Kenallove tau c = 0,17.
Spracoval Róbert Hanák, Február 2016